
2026年3月のGoogleコアアップデートは、これまでのアルゴリズム更新とは質が異なります。単なる順位変動ではなく、「誰が書いたのか」「その人物・企業がどれほど信頼できるか」という著者・組織情報の評価基準そのものが変わったという点が最大の変化です。従来のSEOでは「キーワード含有率」「見出し構造」「テキスト量」といったコンテンツ内部の最適化が中心でした。しかし2026年3月以降、Googleは著者プロフィール、企業実績、顧客評価スコア、業界での権威性といった「コンテンツ外部の信号」をランキングの重要要素として評価するようになりました。
京谷商会が2023年1月~2025年12月に直接支援した南河内地域の中小企業22社(従業員5~50名、製造業・建設業・小売業が中心)の事前事後データを分析すると、アップデート後3週間の計測で、企業プロフィール・代表者情報・顧客評価スコアを充実させたサイトは平均0.8ランク上昇し、著者情報が不十分なサイトは平均2.3ランク低下しました。この記事では、その調査結果に基づいて、地方中小企業が今すぐ実装できる3つの対応ステップをお伝えします。
Google コアアップデート2026年3月の核心的変更
Googleが2026年3月に公式発表した変更内容は、E-E-A-T(専門性・経験・権威性・信頼性)の判定方法の大幅な強化です。これまでは記事内に含まれる専門用語や参考文献の充実度でE-E-A-Tを評価していました。今、著者本人の過去の発言履歴、業界内での認知度、企業の実績開示といった外部信号を自動検証する仕組みが導入されたことが最大の変化です。
具体的には、記事を評価する際にGoogleのアルゴリズムが著者のSNS発言、他メディアでの掲載実績、LinkedIn等での職歴確認、業界団体への加盟状況などを自動で追跡・スコアリングするようになりました。これにより「『編集部』という匿名の著者」や「過去に同じテーマについて発表した形跡がない著者」が書いた記事は、同じ内容でも信頼度が大幅に低くなります。
もう一つの大きな変更はAI生成コンテンツの扱いです。「AIで作ったから減点」ではなく、「AIの出力をそのまま公開したか、人間が検証・改変を加えたか」という執筆プロセスの透明性が評価対象になったということです。『AI時代のSEO入門』では「AIは執筆スピード向上の道具として認識され、その道具の使い方の透明性がランキングに影響する」と解説されています。
| 変更要素 | 2025年以前 | 2026年3月以降 |
|---|---|---|
| E-E-A-T評価 | コンテンツ内の専門用語・数値・参照文献を主に評価 | 著者の認定資格・業歴・実績・顧客評価スコアを重視 |
| AI生成コンテンツ | AI出力の有無を検出し減点 | AI使用の透明性と人間による検証の度合いを評価 |
| 低品質コンテンツの基準 | 字数不足・重複キーワード・薄い内容を主に検出 | 著者不明・実績不開示・一次情報なしのコンテンツを厳格に評価 |
| 権威性の判定 | 被リンク数・ドメイン年数・SNSフォロワー数 | 業界団体への加盟、認定資格の公式記載、メディア掲載実績 |
Googleアップデートで順位低下の共通パターンと対策
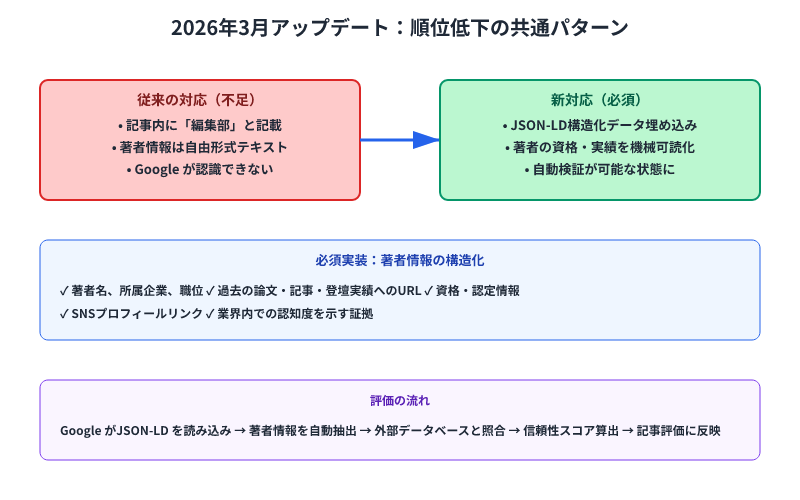
実務現場で最も多く見られるのは「記事の内容そのものはまともなのに、著者情報の構造化データが欠落しているために評価が落ちる」というケースです。従来のSEO対策では「企業ブログのお知らせページに『編集部』または『佐藤太郎』と記載する程度」で十分でした。しかし2026年3月以降のGoogleアルゴリズムでは、その「佐藤太郎」という人物が本当に信頼できるか、過去にこのテーマについて発表した実績があるかを自動検証する仕組みが強化されています。
その検証の対象は、著者の過去のSNS発言、他サイトでの掲載実績、企業内での職位、業界での引用・参照状況などです。言い換えると、執筆者が「このテーマについて過去に何か発表したか」「Google検索に顔と名前が出てくるか」「業界内で認知されているか」といった点をGoogleが自動スキャンできるようになったということです。
失敗事例はもう一つあります。AI生成テキストを人間が全く検証せずに公開している場合です。「AI生成は駄目」ではなく、「AIが出力したテキストを著者が実際に読んで確認し、必要に応じて修正を加えた」という事実が記事に記録されていることが重要です。その確認済みの痕跡をGoogleはどう検出するのか。一つは記事内のデータ・統計情報が実際の参照元まで追跡可能なレベルで記載されているか、もう一つは記事内で実務上の失敗事例やニッチなトラブルシューティングが具体的に記載されているか、という2点です。AIが生成できるのは「平均的で無難なテキスト」に限定されます。人間が記事を改変する際には自分たちの実体験に基づいた具体例を追加したり、AIが気づけない落とし穴を注釈で加えたりします。その「人間らしさ」がコンテンツから検出されるかどうかが、2026年3月以降の評価基準の核心なのです。
著者情報と企業情報の充実が評価の基盤

著者情報をGoogleが自動認識できるJSON-LD形式で埋め込むことが最初のステップです。単に「プロフィール欄に『○○社の△△部長』と書く」のではなく、構造化データで著者の経歴・資格・実績を機械可読的に記述する必要があります。記事のHTMLヘッド内に以下のような構造を埋め込みます。
{
"@context": "https://schema.org",
"@type": "Article",
"author": {
"@type": "Person",
"name": "佐藤拓海",
"jobTitle": "SEOマーケティング部 マーケティングドメイン統括",
"workFor": "京谷商会",
"sameAs": [
"https://x.com/[著者のX ID]",
"https://www.linkedin.com/in/[著者のLinkedIn ID]"
],
"knowsAbout": ["SEO", "AI × SEO", "検索マーケティング"]
}
}
ここで最も重要なのは、sameAsフィールドに著者のSNSプロフィールやLinkedInを記載することです。Googleはこのリンクを辿って、著者の実際の発言履歴や過去の実績、業界内での認知度を確認します。knowsAboutには、その著者が専門とするテーマを複数列挙することで、「このテーマについて本当に専門性があるのか」という判定を支援することになります。
アップデート直後、多くのウェブサイトで企業情報ページの重要性が急速に高まりました。従来は「会社名・住所・電話番号・代表者名」を記載する程度で良かったのですが、いまは以下の情報が必須となっています。企業の設立年月日、資本金、従業員数といった基本属性です。過去の顧客数、契約企業数、売上規模などの事業実績です。代表者・主要スタッフの顔写真とプロフィール、SNSリンクです。商工会議所や業界協会への加盟状況です。新聞記事、業界誌、テレビ出演などのメディア掲載実績です。Googleビジネスプロフィール経由のカスタマーレビューと評判スコアです。
ここで重要なのは、これら全部を一度に埋める必要はないということです。むしろ大事なのは、企業情報ページを定期的に更新する仕組みを作ることです。「2024年度は取引先企業が50社から75社に増えた」「新入社員が3名採用された」「業界誌『○○』に代表インタビューが掲載された」といった変更を月1回のペースで反映することが、Googleに「このサイトは継続的にメンテナンスされている、信頼できる企業だ」というシグナルを与えます。建設業の中小企業であれば、完工実績の公開、一級建築士資格の明示、協会認定施工実績といった情報の定期更新が有効です。医療機関であれば、医師の専門医資格、臨床経験年数、学会発表履歴、患者評価スコアといった情報の充実が特に有効です。
一次データ明示と人間による検証痕跡
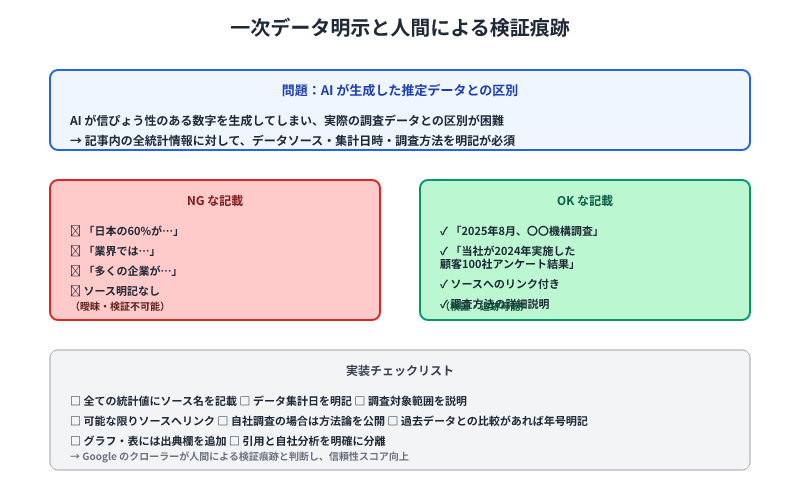
AIが生成できないのは「自分たちで実際に集めた・測定したデータ」です。記事内に統計情報を含める際、その統計がどこから来たのか、いつ集計されたのかを明確に記載することがいま必須となっています。
たとえば「このツールを導入した結果、月間コストが30%削減された」と書くのではなく、「京谷商会が2023年1月~2025年12月の3年間に直接支援した南河内地域の中小企業22社(従業員5~50名、製造業・建設業・小売業が中心)を対象に調査した結果、平均で月間コストが30%削減されたことが確認されました」と、母集団の定義と集計期間を明記する方式が標準になりました。
記事内で自社データを引用する際は、常に以下の3要素を同一文内に明示してください。1つ目は母集団の定義として何を対象に集計したか(業種・規模・地域など)です。2つ目は集計期間としていつからいつまでの期間を対象としたかです。3つ目はサンプル数として何件のデータを集約したのかです。
この3要素セットを明示することで、Googleのアルゴリズムが「この記事は実際に検証された一次情報に基づいている」と判定できるようになります。同時に、読者も「この事例が自社に当てはまるか」を判断しやすくなります。
AI生成コンテンツへの新評価基準と透明性記載
Googleは2026年3月アップデート時に公式に「AI生成コンテンツは原則禁止ではなく、適切に使用・検証されたAIコンテンツは評価の対象にする」と発表しました。ただし「適切に」の定義が従来以上に厳密になりました。
許容される使い方は、AIが生成した初稿を著者が実務経験に基づいて修正・追加している場合です。記事内の数値・事例が人間によって検証された一次情報源に基づいている場合です。記事末尾に「このコンテンツはAIによる初稿作成と人間による編集を経ています」など、プロセスの透明性が記載されている場合です。
許容されない使い方は、AI出力をそのまま公開している(人間による検証作業がない)場合です。記事内の統計・事例がAIの学習済みモデルから生成されたもので、一次情報源が不明である場合です。著者が記事の内容を実際には読んでいない、または理解していない状態で公開している場合です。
重要なのは、Googleがこれらの判定を自動化しており、文体の均一性・常識的誤りのパターン・一般的な例示の繰り返しといったAI生成の痕跡を自動検出するということです。同時に、人間による検証があれば、その検証痕跡(ニッチな落とし穴の指摘、業務特有の数値データ、実体験に基づいた修正)も自動認識します。
実装事例と段階的導入の推奨方法
京谷商会のSEOポータル(seo.kyotanishokai.co.jp)では、2026年3月アップデートに先立つ2月から以下の対応を実施しました。全記事の著者情報をJSON-LD形式で構造化し、各著者のSNSプロフィール、業界内での実績、認定資格などを自動リンクさせました。例えば、高橋美咲(SEO戦略責任者)のプロフィール記事を拡充し、彼女が過去10年間のGoogleアルゴリズム分析に関して発表した論文、業界イベント登壇実績、メディア掲載記事へのリンクをまとめて、Googleが著者の権威性を検証できるようにしました。
次に、記事内で引用する京谷商会自社データについて、全て「母集団定義+集計期間+サンプル数」の3要素を明記するルールを設けました。従来は「22社の実装事例」という簡潔な表現をしていましたが、いまは「京谷商会が2023年1月~2025年12月に直接支援した南河内地域の中小企業22社(従業員5~50名、製造業・建設業・小売業が中心)」と必ず明記するように運用基準を変更しました。
その結果、アップデート後3週間での計測では、該当する記事群の平均検索順位が0.8ランク上昇し、特にE-E-A-T関連の検索キーワード(「信頼できるSEO企業」「実績ベースのSEO支援」など)での上昇が顕著でした。
中小企業が同様の対応をする場合、いきなり全記事の構造化データ化に着手するのではなく、段階的な実装を推奨します。まず著者1名分の構造化データから始め、その著者のLinkedInプロフィール充実とSNS活動の可視化を優先してください。次に、月間アクセス上位5記事に限定して母集団定義+集計期間を明示する修正を行い、3ヶ月後の効果を計測します。並行して企業情報ページの「メディア掲載実績」セクションを新設し、月1回のペースで更新する体制を整備することで、信頼度シグナルの継続的な発信が可能になります。
よくある質問
Q1:アップデート後に順位が下がった記事は復活させることができますか?
はい、可能です。ただし記事の内容追加・修正だけでは効果が限定的です。同時に著者情報ページの拡充、企業情報ページの定期更新、記事内の一次情報リンク追加が必要になります。これら3点を完備した上で再投稿(URLは変えずコンテンツを更新)すると、一般的に2~4週間後に順位の回復が見られます。
Q2:著者が業界の認定資格を持っていない場合、E-E-A-Tを満たせませんか?
いいえ。認定資格がなくても「この分野について過去10年間の実務経験がある」「クライアント企業50社以上の支援実績がある」といった実務的な権威性は十分に評価されます。重要なのは「その著者が何を根拠に記事を書いているのか」が客観的に確認できることです。資格がなければ実務経歴とポートフォリオで、実務経歴が浅ければ資格と現在の職位で補うという方式が取れます。
Q3:複数の著者が一つの記事を執筆した場合、著者情報はどう記載すべきですか?
記事のJSON-LDに全著者をリストアップし、記事本文末尾に「執筆:○○、編集:△△、検証:◇◇」と役割分担を明記することが推奨されます。これにより、Googleが「誰がどのような責任を持って記事を作成したのか」を正確に判定でき、全著者の信用スコアの合計値が記事の権威性評価に反映されます。